Inspiriert von SEOmoz habe ich mir heute mal die Crawling-Fehler großer Seiten in den Google Webmaster Tools etwas genauer angesehen.
Viele Inhouse SEOs kennen das wahrscheinlich nur allzu gut: Man wagt einen Blick in die Google Webmaster Tools und findet dort eine ungeheure Anzahl an Crawling-Fehlern vor und weiß gar nicht, wo man mit dem Fixen dieser Fehler anfangen soll.
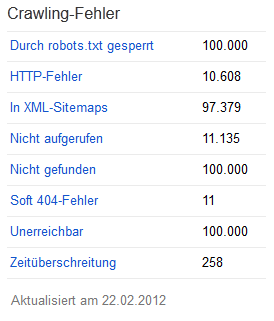
Tatsächlich sollte man sich in Anbetracht dieser überwältigenden Anzahl an Fehlern einen Plan zurechtlegen, nach welchem man vorgehen möchte. Das kann natürlich auf verschiedene Art und Weise geschehen. Eine mögliche Vorgehensweise möchte ich hier kurz vorstellen.
1. In XML-Sitemaps
2. Durch robots.txt gesperrt
3. http-Fehler
4. Nicht gefunden
5. Soft-404-Fehler
6. Nicht aufgerufen
7. Unerreichbar / Nicht erreichbare URL
8. Zeitüberschreitung
1. In XML-Sitemaps
Da es sich bei Crawling-Fehlern innerhalb von XML-Sitemaps um Fehler handelt, die relativ einfach behoben werden können, würde ich mit diesen Fehlern anfangen.
Wie kommt es zu diesen Fehlern?
Immer wieder werden veraltete XML-Sitemaps auf dem Server vergessen, bzw. bewusst dort liegen gelassen, da sie “ja niemanden stören und wer weiß… vielleicht braucht man sie ja irgendwann mal wieder”. 😉 Das ist vorrübergehend sicher auch in Ordnung, allerdings sollten diese Sitemaps dann aus den Google Webmaster Tools ausgetragen werden.
Auf SEOmoz schreibt Joe Robison, dass Google regelmäßig auch XML-Sitemaps crawlt, die bereits aus den Google Webmaster Tools ausgetragen wurden. Er rät dazu, diese Sitemaps mit einem 404-Status auszuliefern und nicht an die aktuelle XML-Sitemap weiterzuleiten. Der Crawler erkennt dann nach mehrmaligem Crawlen, dass die Sitemap nicht mehr gültig ist und crawlt diese dann nicht mehr.
Häufig kommt es auch vor, dass das CMS bzw. das Skript, welches für die automatische Generierung der XML-Sitemaps verwendet wird, falsche URLs erzeugt und somit tausende Seiten mit Status-Code 404 bei Google eingereicht werden. Das sollte natürlich nicht passieren. Alle Skripte, die zur Generierung von XML-Sitemaps verwendet werden sollten regelmäßig überprüft und validiert werden.
Bei diesen beiden Punkten handelt es sich um die häufigsten Ursachen für falsche URLs in den XML-Sitemaps. Das Schöne daran ist, dass diese Punkte in der Regel ohne größeren Aufwand zu beheben sind.
Hinweis: Es macht nur Sinn, XML-Sitemaps in den Google Webmaster Tools zu hinterlegen, wenn diese auch auf dem aktuellsten Stand sind und ausschließlich Seiten mit gutem Content enthalten. Es sollten auf gar keinen Fall Sitemaps mit massenweise nicht mehr existierenden Seiten oder Seiten mit “dünnen” Inhalten eingereicht werden.
2. Durch robots.txt gesperrt
Hierbei handelt es sich im Grunde eigentlich nur um eine Information und weniger um einen tatsächlichen Crawling-Fehler. Denn wenn einzelne Seiten oder ganze Bereiche einer Webseite via robots.txt für den Crawler gesperrt werden, ist das in der Regel so gewollt und Google hält sich dann natürlich auch weiterhin an diese Anweisung. Nichts desto trotz sollte auch diese Liste im Auge behalten und die robots.txt-Datei regelmäßig überprüft werden. In der Regel ist hier jedoch nicht viel zu tun.
Hinweis: Als von der robots.txt-Datei blockiert werden laut Google auch solche URLs angesehen, die auf eine durch die robots.txt-Datei blockierte URL weiterleiten. Im robots.txt-Analyse-Tool werden diese URLs jedoch als “zugelassen” angezeigt.
3. HTTP-Fehler
Unter “HTTP-Fehler” werden Seiten aufgelistet, die Anfragefehler wie zum Beispiel 403 Forbidden oder 400 Bad Request zurückliefern. Diese Seiten sollte man sich genauer ansehen und nach der Ursache für den jeweiligen HTTP Statuscode suchen. Eine Übersicht über die wichtigsten HTTP Statuscodes gibt es direkt bei Google.
4. Nicht gefunden
In der Kategorie “Not found” listet Google uns alle Seiten auf, die während des Crawlings nicht gefunden werden konnten. Es handelt sich dabei also um die klassischen 404-Fehlerseiten, die den Statuscode 404 Not found zurückliefern. Zu diesen Fehlern kommt es in der Regel in folgenden Fällen:
- Eine bestehende Unterseite wird gelöscht und es wurde vergessen eine Weiterleitung einzurichten.
- Die URL einer Seite wurde geändert und es wurde keine Weiterleitung der alten URL auf die neue URL eingerichtet.
- Wir haben einen Tippfehler in einem Link auf eine unserer Unterseiten und verweisen dadurch auf eine Seite die nicht existiert.
- Ein externer Link enthält einen Tippfehler und verweist deshalb auf eine nicht existente Unterseite unserer Website.
- Wir haben die Domain gewechselt und die neue Verzeichnisstruktur passt nicht exakt zur alten.
Es geht also nicht nur um Seiten, die es mal gab und die jetzt weg sind – sondern auch um interne oder externe falsch oder falsch geschriebene Links.
Wie sollten 404-Fehler behandelt werden?
Insbesondere nach der Migration der kompletten Website auf eine neue Domain oder nach einem großen URL-Redesign kommt es häufig zu mehreren tausend 404-Fehlern. Nicht immer ist es möglich, alle Seiten via 301-Redirect an die entsprechenden neuen Seiten weiterzuleiten. Wichtig ist dann, dass man sich die alten URLs genau ansieht und überprüft, welche dieser alten URLs am besten verlinkt sind. Das bedeutet also:
- Unterseiten mit starken Backlinks: Wir suchen uns Unterseiten heraus, die sehr starke Links haben – beispielsweise einen Link aus der Wikipedia oder von einer anderen trusted Domain.
- Unterseiten mit sehr vielen Backlinks: Außerdem suchen wir nach alten URLs, die sehr viele Backlinks von externen Quellen erhalten haben.
WIE FINDEN WIR DIE AM BESTEN VERLINKTEN UNTERSEITEN?
Zum Auffinden der am stärksten verlinkten Unterseiten gibt es eine ganze Reihe von Tools. Natürlich können wir diese hier nicht alle aufzählen und möchten deshalb nur ein paar dieser Tools nennen:
- Google Webmaster Tools: Direkt von Google und außerdem absolut kostenlos. Unter “Ihre Website im Web” -> “Links zu Ihrer Website” -> “Ihr am meisten verlinkter Content” erhalten wir eine riesige Liste unserer am meisten verlinkten Unterseiten.
- Link Research Tools: Mit Hilfe des “Strongest Sub Pages Tool” aus den Link Research Tools können ebenfalls die stärksten Unterseiten analysiert werden.
- Searchmetrics Essentials: In den Searchmetrics Essentials findet man die am häufigsten verlinkten Seiten unter “Links” -> “Verlinkte Seiten”.
- Sistrix Toolbox: In der Sistrix Toolbox unter “Links” -> “Linkziele”.
- strucr.com: Auch mit strucr.com erhält man einige sehr interessante Daten zur Website-Struktur. Natürlich auch welche Seiten am stärksten verlinkt sind. Wobei sich das jedoch auf die interne Verlinkung bezieht. Hier gibt’s mehr zum Thema Webseiten-Struktur analysieren mit strucr.com.
Daraus ergibt sich dann eine Liste mit den “wichtigsten” Unterseiten. Wichtig ist nun, dass wir zumindest für diese Seiten eine 301-Weiterleitung der alten URL auf die entsprechende neue URL einrichten. Denn diese URLs erhalten durch die eingehenden Links nicht nur den ein oder anderen Besucher, sondern natürlich auch wichtigen Linkjuice, der durch die 301-Weiterleitung dann an die neue URL weitergegeben wird.
WORAUF SOLLTE UMGELEITET WERDEN?
Am besten bleiben natürlich alle Inhalte bestehen und man leitet die alten URLs einfach 1:1 auf die neuen URLs um. Das ist aber nicht immer möglich, denn oft fallen durch eine Migration oder ein URL-Redesign einzelne Seiten oder ganze Bereiche komplett weg. Dann sollten die alten URLs möglichst sinnvoll auf neue URLs mit zumindest sehr ähnlichem Content weitergeleitet werden. Ist das nicht möglich, weil es auf der neuen Seite keinen Content dieser Art mehr gibt, sollten die alten Seiten auf übergeordnete Seiten oder die Startseite weitergeleitet werden. Wobei es immer das Ziel sein sollte, den weitergeleiteten Besucher (und auch den Googlebot) auf relativ ähnlichen Content zu führen.
Aus Gründen der Performance kann es gerade bei großen Seiten auch ratsam sein, nur die wichtigsten Seiten umzuleiten und die weniger wichtigen Seiten als 404-Seiten stehen zu lassen. Der Googlebot erkennt diese dann im Laufe der Zeit und weiß, dass sie nicht mehr für wichtig erachtet werden.
Hinweis: Hingegen der weit verbreiteten Theorie, 404-Seiten wären schädlich für eine Seite, hat sich Google dazu im hauseigenen Blog gemeldet und erklärt, dass 404-Fehlerseiten ein ganz normaler Bestandteil einer Webseite sind: Do 404s hurt my site? Wie eine nützliche 404-Seite aussehen soll, erklärt Google übrigens hier: Erstellen nützlicher 404-Seiten.
5. Soft 404-Fehler
Neben den 404-Seiten weist Google außerdem noch sogenannte Soft-404-Fehler aus. Damit sind Seiten gemeint, die dem User signalisieren sollen, dass die angeforderte Seite nicht gefunden wurde. Also Seiten, die den selben oder ähnlichen Content wie eine 404-Seite enthalten, allerdings keinen entsprechenden HTTP Statuscode zurückliefern. Eine Seite die den User auf nicht mehr existierenden Content hinweist, sollte also immer mit Statuscode “404 Nicht gefunden” oder “410 Gelöscht” ausgeliefert werden. Mehr zum Thema falsche 404-Seiten direkt bei Google.
6. Nicht aufgerufen
In der Kategorie “Nicht aufgerufen” listet Google alle Seiten auf, die von Google aus irgendwelchen Gründen nicht vollständig aufgerufen werden konnten. Neben der jeweiligen URL zeigt Google auch einen Hinweis auf die mögliche Ursache an. In dieser Kategorie befinden sich hauptsächlich Weiterleitungsfehler.
Google unterscheidet dabei folgende Weiterleitungsfehler:
- Weiterleitungsfehler: die Weiterleitungen auf der Seite konnten von Google nicht vollständig verfolgt werden. Das kann verschiedene Gründe haben. Generell sollte beachtet werden, dass nicht kaskadierend weitergeleitet werden sollte. Stattdessen sollte direkt von Seite A(lt) auf Seite N(eu) weitergeleitet werden. Der Umweg von Seite A(lt) über Seite E(twas neuer) hin zu Seite N(eu) sollte also vermieden werden. Auch der Weiterleitungs-Timer sollte möglichst kurz sein. Außerdem sollte nicht mittels Meta-refresh weitergeleitet werden.
- Fehler in Weiterleitungsschleife: dieser Fehler wird angezeigt, wenn Google einer Weiterleitung folgt und diese mehrmals auf sich selbst verweist. Auch Weiterleitungsschleifen sollten unbedingt vermieden werden. Hier die offizielle Aussage von Matt Cutts zum Thema Wie viele 301 Weiterleitungen kann ich auf einer Website erstellen?.
- URL für Weiterleitung ist zu lang: eine URL sollte höchstens 255 Zeichen lang sein. Diese Länge kann beispielsweise überschritten werden, wenn bei einer Weiterleitung automatisch eine Session-ID angehängt wird. Der Googlebot sollte Seiten ohne Session-IDs oder andere Argumente crawlen können.
- Ungültige Weiterleitung: Die angelegte Weiterleitung führte zu einer nicht existierenden Seite. Logischerweise sollten Weiterleitungen immer getestet und überprüft werden, damit sichergestellt werden kann, dass diese funktionieren.
- Leere Weiterleitung: Dieser Hinweis erscheint, wenn Google eine Weiterleitung findet, die jedoch auf keine andere Webseite verweist. Alle Weiterleitungen sollten auf gültige Seiten verweisen.
- Cookie-Fehler: der Googlebot surft ohne Cookie-Unterstützung, deshalb kann es zu Problemen und Einschränkungen kommen, wenn eine Website Cookies für die Navigation verwendet. Google empfiehlt hier die eigenen Seiten mit einem Textbrowser zu überprüfen, um eventuelle Hindernisse festzustellen.
Wer mehr zum Thema Fehler wegen nicht aufgerufener URLs lesen möchte, kann sich auch hierzu direkt bei Google informieren.
7. Unerreichbar / Nicht erreichbare URLs
Hier sammelt Google eine Liste der URLs, die beispielsweise aufgrund eines DNS-Fehlers oder einer Zeitüberschreitung nicht aufgerufen werden konnten. Eine Möglichkeit für das Auftreten dieser Fehler könnte eine Überlastung des Servers zur Zeit des Crawling-Vorgangs sein.
Google gliedert die Fehler für nicht erreichbare URLs in folgende Kategorien:
- Fehler 5xx: Fehler mit einem 500er-Statuscode werden meist bei einer Überlastung des Servers oder einem internen Serverfehler ausgegeben.
- Problem mit DNS: es war keine Verbindung zum DNS-Server möglich. Mögliche Ursachen könnten ein inaktiver Server oder eine falsch aufgelöste Domain sein.
- Die Datei “robots.txt ist nicht erreichbar.: bevor der Googlebot die Seite crawlt, sieht er sich die robots.txt-Datei an, um festzustellen welche Bereiche der Website für ihn tabu sind. In diesem Fall konnte er die robots.txt-Datei nicht aufrufen und versucht es später erneut. Hinweis: der Googlebot erkennt, ob die robots.txt-Datei nur nicht erreichbar ist oder ob diese gar nicht angelegt wurde.
- Netzwerk nicht erreichbar: ein Grund für einen Netzwerkfehler könnte beispielsweise eine Zeitüberschreitung aufgrund zu langsam reagierender Seiten sein oder ein den Web-Crawler blockierender Hosting-Server.
- Verbindung konnte nicht aufgebaut werden.
- Keine Antwort: Der Server hat keine Antwort erhalten.
- Abgeschnittene Antwort: die Verbindung wurde vom Server geschlossen, bevor die Antwort vollständig übertragen wurde.
- Verbindung zurückgewiesen
- Abgeschnittene Kopfzeilen
Weiter Informationen zum Thema Fehler durch nicht erreichbare URL.
8. Zeitüberschreitung
In der letzten Kategorie von Crawling Fehlern weist Google Seiten aus, bei deren Zugriff eine Zeitüberschreitung auftrat. Auch hierfür kann es wieder mehrere Ursachen geben.
- Zeitüberschreitung bei DNS Lookup
- URL-Zeitüberschreitung
- robots.txt-Zeitüberschreitung
Fazit
Mit den Google Webmaster Tools liefert uns Google wirklich eine Menge an wertvollen Informationen, die wir auch nutzen sollten um unsere Webseiten zu verbessern. Denn im Grunde geht es Google ja immer um den User und dessen Zufriedenheit. Insbesondere die Crawling Fehler spielen dabei natürlich eine wichtige Rolle, denn wer schickt seine User schon gerne auf eine Fehlerseite?