
Im 6. Teil unserer SEO Check-Serie haben wir beschrieben, wie eine Webseite aufgebaut sein muss, damit Google den darauf befindlichen Content crawlen und die User diesen finden können. Dafür gibt es natürlich auch ein paar Tools, die einen SEO bei der Strukturierung der Webseite unterstützen. Eines dieser Tools haben wir uns etwas genauer angesehen und möchten unsere Erfahrungen hier mit euch teilen. Es handelt sich dabei um strucr.com, einen Webservice der AmbiWeb GmbH. Was das Tool kann und welche interessanten Informationen es über die Struktur einer Webseite liefert haben wir hier für euch aufgeschrieben. Los geht’s!
- Dashboard
- Einstellungen
- Crawl-Vorgang
- Crawl-Report
- Content-Distribution
- Links
- PageRank
- CheiRank
- 2D-Rank
- Sonstiges
- Fazit
Das Dashboard
Die Oberfläche von strucr.com ist relativ schlicht und funktional gehalten. Nach dem Login erhält man auf dem Dashboard einige Details zum Account.
Unter “Your Sites” werden die bereits eigetragenen Seiten aufgelistet. Durch einen Klick auf “Crawl this site” kann direkt ein Crawl der jeweiligen Seite gestartet werden. Direkt rechts neben den Seiten, können die Stati der letzten fünf Crawls eingesehen werden.
Darunter besteht jeweils die Möglichkeit eine neue Seite, bzw. einen neuen Crawl hinzuzufügen.
Crawl Settings
Vor dem Crawlen einer Seite können noch ein paar Details eingestellt werden. Neben der maximalen Crawl-Tiefe können auch die Crawl-Geschwindigkeit und die maximale Anzahl an Seiten bestimmt werden. Außerdem hält sich der Crawler laut strucr.com strikt an die robots.txt-Datei. Deshalb kann im letzten Punkt auch noch ausgewählt werden, an welche robots.txt-Regeln er sich halten soll. Zur Auswahl stehen neben dem Strucr Crawler (strucr), Google (Googlebot), Bing (bingbot) sowie Anybody (*).
Der Crawl-Vorgang
Der Crawl startet kurz nachdem er angestoßen wurde und beginnt dann die Seite entsprechend der Crawl Settings zu crawlen. Nachdem der Crawler mit seiner Arbeit fertig ist, müssen die Ergebnisse verarbeitet werden. Das passiert im Wesentlichen in drei Schritten.
- Preprocessing: In dieser Phase werden für alle Seiten die eingehenden und ausgehenden Links berechnet (follow und nofollow).
- Calculating: Es werden für alle Seiten die PageRank und CheiRank-Metriken berechnet. Hierfür sind mehrere Iterationen notwendig, wovon höchstens 30 Iterationen durchgeführt werden.
- Postprecessing: Anschließend wird der 2D-Rank berechnet.
WIE LANGE DAUERT DER CRAWL-VORGANG?
Die Dauer des Crawl-Vorgangs hängt selbstverständlich von der Größe der Seite und den getätigten Einstellungen ab. Für das SEO Book hat der Crawler 25 Minuten und 18 Sekunden gebraucht und hat dabei 891 Seiten mit insgesamt 47.535 Links gecrawlt. Für die Berechnung der Ergebnisse sind dann noch einmal knapp 5 Minuten vergangen. Es lässt sich also schlecht sagen, wie lange es dauert, bis eine Seite mit Strucr.com analysiert wurde. Tobias Schwarz von der AmbiWeb GmbH (strucr.com) verrät uns auf Anfrage:
Da es wirklich viele Variablen gibt ist es sehr schwer zu sagen wie lange ein Crawl dauert. Bei richtig großen Seiten (10 Millionen Unterseiten) kann es schon mal sein, dass man mehr als 1 Woche crawlt und dann auch mehr als eine Woche dran rechnet um die Metriken zu haben.
Der Crawl Report
Nachdem die Seite gecrawlt und die Ergebnisse berechnet wurden, können diese im Crawl Report eingesehen werden. Die Daten sind dort nach verschiedenen Kriterien sortiert und aufgelistet, wobei die meisten davon eine selbsterklärende Überschrift erhalten haben. So verrät zum Beispiel die Überschrift “Pages By Status” bereits, was es mit den Daten auf sich hat. Gleiches gilt für “Pages By HTTP Status”.
Das Interessante daran ist, dass durch einen Klick auf einen dieser Stati alle dazugehörigen Seiten aufgelistet werden. Klickt mal beispielsweise auf “301”, erhält man alle 51 Seiten, deren Header einen 301 Status zurückliefert.
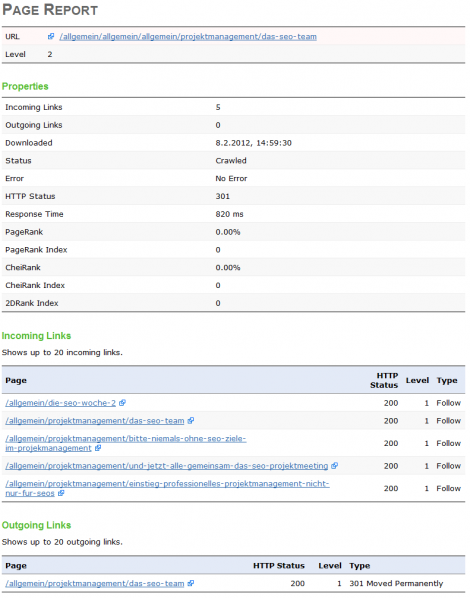
PAGE REPORT
Klickt man auf dieser Übersicht dann auf eine der Seiten, so erhält man detaillierte Informationen über die Anzahl eingehender Links, die Anzahl ausgehender Links, die Antwortzeit, den PageRank und vieles mehr (siehe Screenshot).
PAGEY BY RESPONSE TIME
Im nächsten Abschnitt werden die Seiten nach ihrer Antwortzeit kategorisiert. Diese Zahlen eignen sich hervorragend um langsam ladende Seiten zu identifizieren, die dann im Anschluss genau analysiert werden können. Wie lange eine Seite im Detail lädt, erfährt man, indem man zuerst die entsprechende Kategorie, also z. B. “5000-10000 ms”, auswählt und auf der nächsten Seite dann die jeweilige Seite wählt. Damit man auf den ersten Blick sieht, wie es um die Antwortzeiten der einzelnen Seiten bestellt ist, liefert strucr auch eine entsprechende Grafik, welche die Seiten in fast, medium, slow und critical einteilt.
PAGES BY HINTS
Der nächste Abschnitt ist ebenfalls sehr interessant. Hier erhält man den ein oder anderen “Hinweis”. Wobei mit Hinweisen Dinge wie “<a> links relative” (also Seiten, die relative Links enthalten), “<a> more than 100 links” (Seiten mit mehr als 100 ausgehenden Links) und “URL has non-lowercase elements in path” (also Seiten mit Großbuchstaben oder Sonderzeichen in der URL). Das ist schon wirklich eine interessante Geschichte. Das schöne ist nämlich, dass man immer gleich sieht, bei wie vielen Seiten dieses “Problem” auftritt. So kann man sich jeden Tag eines dieser Probleme vornehmen und deren Ursache beheben. Wobei es sich natürlich nicht immer um Probleme handelt, sondern eben um Hinweise. ![]() Welche Hinweise dabei gegeben werden, kann in der Page Hints-Liste direkt auf strucr.com eingesehen werden.
Welche Hinweise dabei gegeben werden, kann in der Page Hints-Liste direkt auf strucr.com eingesehen werden.
Content Distribution
Unter Content Distribution erfährt man nun etwas über die Zugänglichkeit (accessibility) und Verteilung (distribution) der Seiten. Dazu wird die Seite in Level unterteilt, die Startseite befindet sich auf Level 0, anschließend wird vom Crawler ermittelt, wie die weiteren Seiten erreichbar sind. Alle Seiten, die von direkt einen Link von der Startseite erhalten, befinden sich auf Level 1 und sind somit durch einen Klick erreichbar. Auf Level 2 befinden sich dann Seiten, die von einer Seite des ersten Levels verlinkt werden und so weiter. Neben der absoluten Häufigkeit errechnet strucr natürlich auch die relative Häufigkeit sowie die kumulierte relative Häufigkeit. Mit diesen Werten kann man also auf einen Blick sehen, welche Unterseiten mehr Aufmerksamkeit in Form von Links benötigen. Gerade für wirklich große Seiten dürften diese Werte sehr wertvoll sein, da man hier sofort sieht, wenn die Struktur der Seite umgebaut werden sollte.
OVERALL CONTENT BY LEVEL
Die Tabelle unter Overall Content by Level gleicht der vorherigen Tabelle, also der Tabelle unter “Accessible Pages By Level” sehr stark. Dennoch bestehen hier ein paar kleine, aber feine Unterschiede. Während die erste Tabelle (“Accessible Pages”) nur die Seiten enthält, die auch tatsächlich gecrawlt werden durften, enthält die zweite Tabelle (“Overall Content”) nämlich auch die Seiten die nicht gecrawlt werden durften, weil sie mit nofollow oder via robots.txt vom Crawling ausgeschlossen sind. Außerdem enthält sie auch Dateien, die keine HTML-Seiten waren, also beispielsweise PDF-Dateien, Bilder etc.
PAGES WITH A HIGH LEVEL
Auch hier ist die Überschrift eigentlich schon aussagekräftig genug. Hier werden alle Seiten mit einem hohen Level aufgelistet. Warum sollte jedem SEO klar sein, weil diese Seiten natürlich sehr weit von der Startseite entfernt sind. Deshalb sollten diese Seiten genauer unter die Lupe genommen werden. Wenn es sich um sehr viele Seiten mit hohen Levels handelt, sollte natürlich über eine Änderung der Seitenstruktur nachgedacht werden. Ab welcher Seitenzahl bzw. welchem Level das ist, hängt natürlich stark von der Größe der Seite ab. Ein Onlineshop mit mehreren Millionen Unterseiten kann selbstverständlich keine Struktur abbilden, welche ausschließlich aus 5 Levels besteht, das sollte jedem klar sein.
Links
Hierzu gibt es eigentlich nicht sonderlich viel zu sagen. Hier sind einige Seiten aufgelistet, die sehr viele eingehende Links haben. In der Regel sind das natürlich vor allem die Seiten, die irgendwo in der Navigation bzw. der Hauptnavigation der Seite aufgehängt sind. Dennoch sollten die hier aufgelisteten Seiten hin und wieder durchgesehen werden. Denn unwichtige bzw. weniger wichtige Seiten haben in dieser Liste nichts zu suchen und sollten entsprechend dezenter verlinkt werden.
PageRank
Zum Thema PageRank gibt es in strucr zwei Tabellen. Die erste enthält die Seiten mit dem höchsten PageRank (“Pages With A High PageRank”), wobei hier zu beachten ist, dass es ausschließlich um den “internen PageRank” geht. Also darum, wie gut die Seite intern verlinkt ist. Die zweite Tabelle enthält dann Seiten mit einem hohen PageRank und nur wenigen ausgehenden Links und dürfte damit später für Backlink-Hunter sehr interessant sein. Damit lassen sich dann Seiten identifizieren, von welchen es sich lohnt einen Link abzustauben, wobei hier natürlich auch wieder erwähnt werden muss, dass es sich nur um den internen PageRank handelt, welcher auch gar nichts mit dem Google PageRank zu tun hat. Strucr gibt außerdem immer wieder Hinweise, wie die einzelnen Werte zu deuten sind und was man damit anfangen kann. Bei Seiten mit einem hohen PageRank rät strucr dazu die Usability der Seite zu optimieren um so die Bouncerate bzw. Exitrate auf diesen Seiten so gering wie möglich zu halten. Das macht natürlich Sinn. Denn bei diesen Seiten handelt es sich in der Regel ja um Seiten, die von einem User häufiger zufällig angesurft werden, als andere Unterseiten. Also gilt es hier die potentiellen User auf der Seite zu halten.
CheiRank
Ein ebenfalls sehr interessanter Wert ist der CheiRank einer bestimmten Seite, dieser ist nämlich ein Indikator für wichtige Hub-Pages. Bei Seiten mit einem hohen CheiRank handelt es sich also um starke Hubs innerhalb des internen Linkgraphen. Strucr rät deshalb dazu mehr externe Backlinks von starken Autoritätsseiten bzw. anderen externen Quellen auf diese Seiten zu generieren. Auch für den CheiRank gibt es wieder eine zweite Tabelle, die Seiten mit einem hohen CheiRank und einer nur geringen Anzahl an eingehenden (internen) Links auflistet. Hier könnte natürlich vor allem darüber nachgedacht werden diese Seiten intern zu stärken. Also intern mehr Links auf diese Hub-Pages zu generieren.
2D-Rank
Die letzte Metrik, der 2D-Rank, verknüpft dann die Werte des PageRanks mit den Werten des CheiRanks und macht daraus eine neue, sehr interessante Metrik. Mit dem 2D-Rank können nämlich die wichtigsten Seiten identifiziert werden – klar, dass hier natürlich die Startseite an erster Stelle stehen sollte. Auch hier zeigt strucr.com wieder die 20 besten Seiten in einer Tabelle. In einem Blog sind hier natürlich die ganzen Kategorie- und Tag-Seiten vertreten, da diese sowohl sehr viele eingehende Links (von jedem Artikel, der in dieser Kategorie abgelegt ist, evtl. von der Hauptnavigation etc.) erhalten und gleichzeitig natürlich sehr viele auf Unterseiten enthalten. Bei einem Shop wäre das natürlich sehr ähnlich. Auch dort wäre die Startseite an erster Stelle, gefolgt von den Channel- und Subchannel- bzw. Themenseiten. Genau das ist auch der Grund, weshalb diese Seiten in der Regel für die etwas suchvolumenstärkeren Keywords, wie zum Beispiel “Bücher” oder “DVD” etc. ranken.
Sonstiges
Was gibt es sonst noch so zum Tool zu sagen?
VORERST KEINE PUBLIC CRAWLS
Erwähnt werden sollte noch, dass es vorerst keine “Public Crawls” geben wird. Es können also nur eigene Seiten bzw. Kundenseiten, für welche eine Genehmigung des Kunden vorliegt, gecrawlt werden. Das liegt daran, dass das Tool noch relativ neu ist und so ein Crawler schnell mal eine Seite abschießen bzw. stark beeinträchtigen kann. Sobald die Entwickler von strucr.com diese Probleme zu 100 Prozent ausschließen können, wird es auch möglich sein fremde Seiten mit strucr.com zu crawlen, bis dahin müssen alle Seiten von der AmbiWeb GmbH validiert werden und können erst dann gecrawlt werden. Wobei der User die Validierung auch selbst vornehmen kann, indem er eine Datei hochlädt.
TESTEN NEUER FEATURES
Laut Tobias Schwarz (AmbiWeb GmbH, strucr.com) wird strucr mittlerweile auch gerne dazu benutzt um die Entwicklungsumgebung einer Seite bzw. die Einführung neuer Features auf Fehler zu testen.
Fazit
strucr.com ist ein wirklich großartiges Tool, für alle Inhouse SEOs größerer Seiten, aber auch für Agenturen die sich einen umfassenden Überblick über die Struktur der Kundenseite verschaffen möchten. Wichtig ist dabei, dass man sich die gelieferten Daten auch genau ansieht. Denn wer sich ein wenig in die Zahlen reindenkt, stellt schnell fest, wie er seine Seite verbessern kann. Die dabei entstehenden Erkenntnisse können oft eine große Hebelwirkung haben, denn wer weiß, wie seine Seite funktioniert und welche Unterseiten wichtig und welche weniger wichtig sind, der hat viel gewonnen. Deshalb empfehlen wir allen, die jetzt neugierig geworden sind, strucr.com einfach mal zu testen. Natürlich freuen wir uns auch auf euer Feedback!


