Wann hattest du wie viele Unterseiten im Google Index? Durch wie viele Seiten hat sich der Google-Bot jemals gecrawlt? Und: Wie viele davon hat er wieder verworfen? Was wir bisher nur ahnen konnten, zeigt u ns Google nun mit dem neuen “Indexierungsstatus” in den Google Webmaster Tools.
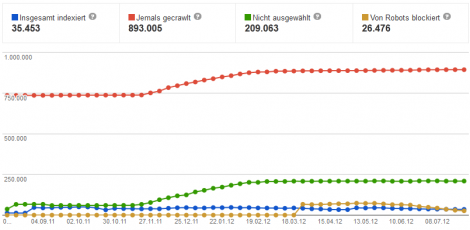
Bis vor Kurzem musste man sich bei der indizierten Zahl der Seiten noch auf die Werte der SEO-Tools (Sistrix, Searchmetrics & Co.) verlassen und erhielt dort teilweise auch sehr ungewöhnliche Werte. Ich habe dabei selbst einige Überraschungen erlebt. Beispielsweise einen SEO-Report, der mir für eine kleine Affiliate-Seite ganze 2 Millionen indexierte Seiten verkaufen wollte. Tatsächlich waren es dann doch nur knapp 800. ![]()
Doch das ändert sich jetzt, denn mit der Einführung des Indexierungsstatus in den Google Webmaster Tools liefert Google nun direkt einige interessante Werte. Allerdings gilt auch hier: Wie bei allem, was von Google kommt, sollte man natürlich auch diese Zahlen mit Vorsicht genießen.
Was liefert uns Google da überhaupt und was lässt sich damit anfangen?
Google gibt folgende Werte preis:
- Insgesamt indexierte Seiten
- Jemals gecrawlte Seiten
- Nicht ausgewählte Seiten
- Von Robots blockierte Seiten
Jemals gecrawlte Seiten
Die Anzahl jemals gecrawlter Seiten stellt logischerweise den höchsten Wert dar. Viel lässt sich daran auf den ersten Blick nicht ableiten.
Erst in Kombination mit den anderen Werten können hier entsprechende Schlussfolgerungen gezogen werden. Warum liegt dieser Wert beispielsweise um ein Vielfaches höher als die Anzahl insgesamt indexierter Seiten?
Nun das kann viele Gründe haben. Zum Einen könnte es ein Indiz für ein oder sogar mehrere URL-Redesigns sein. Google hatte beispielsweise zwei Millionen Seiten der Domain im Index und dann wurde ein umfangreiches URL-Redesign vorgenommen und dadurch änderten sich die URLs und es kam zu zwei Millionen neuen URLs. Dann hat Google logischerweise vier Millionen URLs “gesehen” bzw. gecrawlt, tatsächlich indexiert sind dann aber (hoffentlich!) nur zwei Millionen – und zwar die neuen.
Ein weiterer Grund könnten technische Hürden sein. So könnte es sich bei einer Vielzahl der Seiten um paginierte Seiten, Suchergebnisseiten oder andere Seiten mit Thin Content handeln, die mit Hilfe des Robots-Meta-Tags auf “noindex” gestellt wurden. Google hat diese URLs dann zwar gecrawlt, aber auf Grund der Anweisung nicht indexiert. Ebenso betrifft es URLs, die via Canonical-Tag auf eine andere Seite mit (hoffentlich) dem gleichen Inhalt kanonisieren. Auch diese URLs wurden irgendwann gecrawlt, weil sie irgendwo verlinkt sind, dann jedoch nicht indexiert, weil sich Google – völlig zu Recht – für die kanonisierte URL entscheidet.
Das dürften also die drei gewichtigsten Gründe für einen deutlichen Unterschied zwischen den “jemals gecrawlten” und den “insgesamt indexierten” Seiten sein:
- Einsatz des Canonical-Tags: URLs werden zwar gecrawlt, aber nur die kanonisierte URL wird in den Index aufgenommen.
- Einsatz des Robots-Metatags mit der Einstellung “noindex”: URLs – wie beispielsweise paginierte Seiten – werden zwar gecrawlt, aber nicht indexiert.
- URL-Redesigns: Google kennt die alten URLs, nach einem Redesign sind diese jedoch nicht mehr gültig und es sind nur noch die neuen indexiert.
Insgesamt indexierte Seiten
Hierbei handelt es sich um die zum jeweiligen Zeitpunkt im Index von Google enthaltenen Seiten. Da eine Website in der Regel ständig neuen Content erhält, zeigt dieser Graph also meist einen stetigen Anstieg.
Theoretisch könnte es jedoch auch vorkommen, dass einzelne URLs, bzw. ganze Seitenarten aus dem Index genommen werden. Sei es, weil Google diese Seiten nicht weiter als nützlich ansieht, weil sie zum Beispiel Thin Content oder sogar Duplicate Content enthalten oder weil sich der Seitenbetreiber selbst dazu entscheidet diese Seiten nicht länger für die Indexierung frei zu geben.
Wie bereits unter “Jemals gecrawlte Seiten” beschrieben, werden hier also nur die tatsächlich indexierten URLs gezählt. URLs, die Duplicate Content enthalten, nicht kanonisch oder weniger nützlich sind, sowie Seiten, die via Meta-Tag auf “noindex” stehen, sind hier nicht enthalten. Außerdem könnte natürlich auch ein technisches Problem zu einem unerwünschten Abfallen führen. Dann sollten alle Steuerungsmöglichkeiten (Robots Meta-Tag, Canonical-Tag, robots.txt) genau überprüft werden.
Von Robots blockiert
Unter “Von Robots blockiert” sind alle URLs enthalten, die von Google aufgrund eines entsprechenden Eintrags in der robots.txt-Datei nicht gecrawlt werden dürfen. Diese Information kann insbesondere dann sehr wertvoll sein, wenn ein neuer Eintrag in der robots.txt-Datei hinzugekommen ist, der den Zugriff auf ein bestimmtes Verzeichnis verbietet.
Nicht ausgewählt
Die letzte Kategorie enthält URLs, die nicht indexiert werden, weil es sich dabei um Seiten handelt, die im Wesentlichen anderen Seiten entsprechen und damit Duplicate bzw. Thin Content darstellen, oder Seiten, die zu einer anderen URL weiterleiten.
Auch diese Zahl sollte man selbstverständlich im Auge behalten. Steigt sie stark an, kann das ein Indiz dafür sein, dass Google einen bestimmten Seitentyp als nicht mehr relevant oder sogar als duplicate oder thin ansieht.
Beispiel
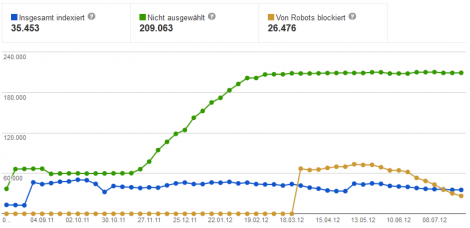
Im vorliegenden Fall zeigt der Indexierungsstatus der Google Webmaster Tools sehr schön, dass hier etwas mit den Indexierungseinstellungen der Website nicht stimmt. Aktuell sind gerade einmal 35.000 URLs indexiert (blaue Linie), während beinahe eben so viele URLs via robots.txt-Datei gesperrt sind (braune Linie) und sogar 6-mal soviele URLs gar nicht ausgewählt (grüne Linie) wurden. Insbesondere der starke Anstieg der nicht ausgewählten Seiten ab Ende November 2011 sollte untersucht werden.
Was sagt Google zur Verwendung der Daten?
- Stetig wachsende Anzahl gecrawlter und indexierter Seiten deutet auf einen regelmäßigen Besuch des Googlebots hin.
- Plötzlicher Abfall indexierter Seiten kann ein Hinweis auf einen überlasteten oder ausgefallenen Server bzw. Zugriffsprobleme sein.
- Eine hohe Anzahl identischer Seiten kann ein Hinweis auf Probleme mit der Kanonisierung oder automatisch generierte Inhalte sein. Google empfiehlt die Benachrichtigungseinstellungen festzulegen, da Google auf solche Dinge auch mit einer Nachricht hinweist.
- Seiten mit eindeutigen Inhalten können laut Google ermittelt werden, indem die Anzahl der indexierten Seiten mit der Anzahl der nicht ausgewählten Seiten verglichen wird.
- Ist ein deutlicher An- oder Abstieg mehrerer Diagramme zum gleichen Zeitpunkt abzulesen, so kann das auf Probleme mit der Website-Konfiguration, mit Weiterleitungen oder Sicherheit hinweisen.
Fazit: Indexierungsstatus in die regelmäßige Beobachtung aufnehmen!
Es gibt also zwei Dinge, die nun zu tun sind: Ihr solltet bei euren Monitoring-Rundgängen nun auch unbedingt den Indexierungs-Status im Blick haben. Gibt es irgendeine sprunghafte Veränderung eines Wertes ist auf jeden Fall eine Recherche nach den Gründen und vielleicht auch auch eine Aktion angesagt.
Und um zweiten sollten wir uns nun alle mal darüber Gedanken machen, woher diese Daten nun plötzlich kommen. Ganz offenbar ist es Google möglich, historisch plausible Zahlen für jede Domain dieser Welt als Graph auszugeben. Das heißt aber auch, dass diese Daten zuvor gespeichert waren. Erste Frage: Welchen Teil des Algorithmus hat der Indexierungsstatus bisher gefüttert? Zweite Frage: Welche anderen historischen Daten hat Google sonst noch in seinem Speicher?
Mehr Informationen zum Indexierungsstatus in den Google Webmaster Tools gibt’s direkt bei Google.