
Wir haben diese Woche die erste SEO Frage erhalten. Katja hat folgende SEO Frage eingereicht:
Ich habe vor ca. vier Wochen eine neue Seite erstellt und prüfe seitdem regelmäßig, ob ich mit dieser Seite bereits Rankings generiert habe und/oder Traffic über diese Seite kommt. Bisher scheint die Seite aber noch nicht zu ranken. Ist es normal, dass es solange dauert, bis man mit einer Seite Rankings aufbaut? Kann man diesen Prozess irgendwie beschleunigen?
Das sind jetzt gleich mehrere Fragen auf einmal. Fangen wir mal damit an, wie du prüfen kannst, ob eine URL überhaupt schon indexiert ist.
Wie kann ich prüfen, ob eine (Unter)seite bzw. eine URL indexiert ist?
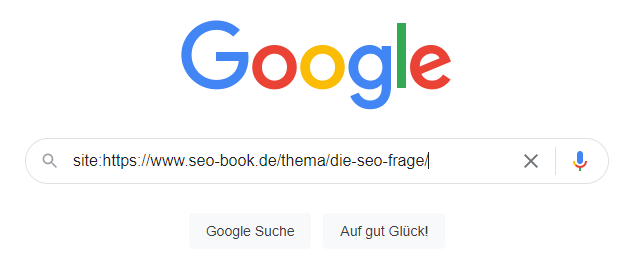
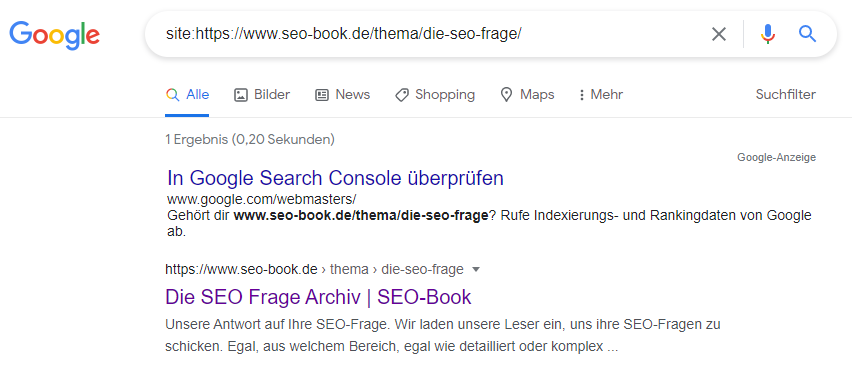
Ob eine bestimmte Unterseite bzw. URL indexiert – also in der Google Datenbank gespeichert und somit über die Google-Suche auffindbar ist – kannst du mit Hilfe des site:-Operators direkt bei Google prüfen. Dazu gehst du wie folgt vor:
- Öffne google.de
- Tippe in das Suchfeld „site:URL“ (Achtung: Die Anführungszeichen musst du weglassen; URL ersetzt du durch deine URL und zwischen site: und der URL wird kein Leerzeichen geschrieben.
- Bestätige die Abfrage durch Drücken der Enter-Taste bzw. mit einem Klick auf „Google Suche“
- Nun erhältst du die zu deiner Anfrage passende Ergebnisliste – oder eine Meldung, dass keine URLs bekannt sind.
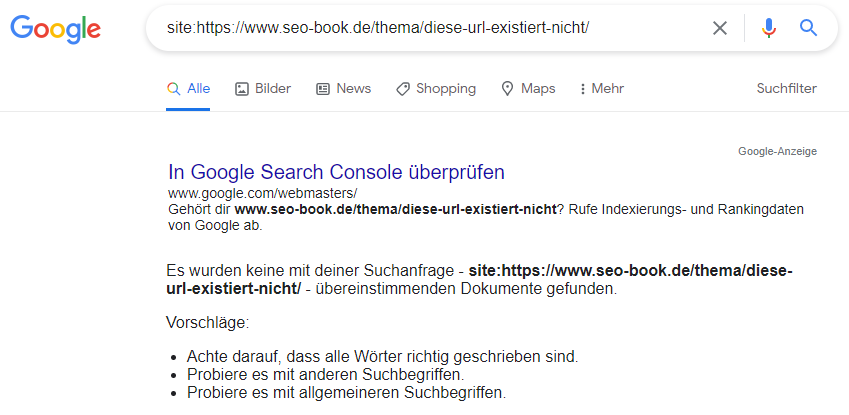
Nun haben wir geklärt, wie du prüfen kannst, ob eine bestimmte URL indexiert ist oder nicht. Als Nächstes wollen wir klären, woran es liegen kann, dass deine URL nicht indexiert ist.
Warum ist meine URL nicht indexiert? Warum wird meine neue Unterseite nicht über die Google Suche gefunden?
Wenn du bereits weißt, dass deine URL nicht indexiert ist, muss im nächsten Schritt geklärt werden, warum sie nicht indexiert ist. Dafür gibt es eine ganze Reihe an Gründen, die wir nachfolgend gemeinsam durchgehen möchten.
- Die URL ist noch ganz neu und Google kennt sie schlicht und einfach noch nicht. Je nachdem, wie regelmäßig du Inhalte veröffentlichst und wie häufig dementsprechend der Crawler / Googlebot bei dir auf der Seite vorbei kommt, kann es mehrere Stunden, Tage oder sogar Wochen dauern, bis Google neue Inhalte findet. Es kann also sein, dass Google deine Website länger nicht gecrawlt und folglich deine neuen Inhalte schlicht noch nicht gefunden hat. Ich zeige dir unten einen Trick, wie du diesen Prozess beschleunigen kannst.
- Die URL ist noch nicht in die interne Verlinkung eingebunden und wird somit vom Crawler nicht gefunden. Damit der Crawler deine Inhalte findet, ist es wichtig, dass die Inhalte möglichst gut gefunden werden. Das kannst du durch eine gute interne Verlinkung unterstützen. Um die Indexierung neuer Inhalte zu beschleunigen, solltest du die neue Seite möglichst prominent verlinken. Dazu bietet sich beispielsweise ein Link von deiner Startseite und/oder von mehreren thematisch relevanten Unterseiten an. Je häufiger und prominenter du die URL intern verlinkst, desto mehr Relevanz erhält sie aus Sicht des Crawlers und desto schneller wird sie von diesem erfasst und in den Index aufgenommen.
- Die URL ist durch technische Maßnahmen von der Indexierung ausgeschlossen. Hier kommen gleich mehrere Einstellungen bzw. Werkzeuge in Frage.
Wichtig ist: Damit eine URL indexiert werden kann, darf sie durch keine der nachfolgend aufgeführten technischen Einstellungen blockiert sein:- „noindex“-Anweisung via Meta Tag / X-Robots Tag: Prüfe, ob die URL mittels Robots Meta Tag (<meta name=“robots“ content=“noindex“>) von der Indexierung ausgeschlossen ist. Achtung: Theoretisch kann diese Einstellung auch via X-Robots-Tag im HTTP Header gesetzt werden. Prüfe die Indexierbarkeit der URL mit einem Crawler (z. B. Screaming Frog, RYTE, etc.), mit der „URL prüfen“-Funktion der Google Search Console oder mit einer Browser-Erweiterung (z. B. Link Redirect Trace). Ist weder im Robots Meta Tag noch im X Robots Tag ein „noindex“ gesetzt, kannst du davon ausgehen, dass die Standardeinstellung „index“ greift.
- Disallow-Anweisung via robots.txt-Datei: Zusätzlich solltest du überprüfen, ob die URL via robots.txt-Datei für das Crawling blockiert ist. Dazu rufst du die robots.txt-Datei deiner Website auf. Diese findest du immer direkt im Root-Verzeichnis (z. B. unter https://www.seo-book.de/robots.txt). Prüfe, ob eine oder mehrere dort hinterlegte Regel(n) das Crawling der gewünschten URL verbieten. Wenn du dir unsicher bist, kannst du auch das mit einem Crawler oder mit dem robots.txt-Tester der Google Search Console überprüfen.
- Canonical Anweisung auf eine andere URL: Außerdem solltest du prüfen, ob die URL ein Canonical Tag enthält, welches auf eine andere Seite verweist. Prüfe dazu im Quellcode, ob du dort folgendes Tag findest: <link rel=“canonical“ href=“https://www.domain.de/pfad-zu-einer-anderen-datei“ />. Wenn die Angabe im Canonical Tag von deiner Wunsch-URL abweicht, ist das für den Crawler ein Signal, dass es sich bei deiner Wunsch-URL nur um eine Kopie handelt. Du empfiehlst dem Crawler mit der Angabe des Canonical Tags die vermeintliche Original-Seite. Google wertet dieses Signal zwar nicht als harte Anweisung, aber als Signal/Empfehlung, dass die andere – im Canonical-Tag angegebene – Seite indexiert bzw. für das Ranking berücksichtigt werden soll.
Achtung: Auch die Canonical Anweisung kann über den HTTP Header gesetzt werden und nennt sich dann HTTP Canonical. Prüfe also nicht nur den Quellcode, sondern auch den HTTP Header! - Statuscode deiner URL: Abgesehen von den Punkten 1 bis 3 solltest du außerdem den Statuscode deiner URL prüfen. Dieser sollte „200 OK“ sein. Sendet deine URL hingegen einen Statuscode 3xx (z. B. 301 oder 302), so wird die URL weitergeleitet und kann dementsprechend nicht indexiert werden. Google indexiert dann in den meisten Fällen das Ziel der Weiterleitung. Sendet die URL Statuscode 4xx oder 5xx (z. B. „404 Not Found“, „410 Gone“), so bedeutet das, dass dem Googlebot mitgeteilt wird, dass die Seite fehlerhaft bzw. nicht mehr vorhanden ist. In diesem Fall wird die URL i. d. R. ebenfalls nicht indexiert. Deine URL sollte also Statuscode „200 OK“ zurück liefern.
So kannst du eine URL überprüfen, ob sie durch technische Einstellungen von der Indexierung (und/oder vom Crawling) ausgeschlossen ist.
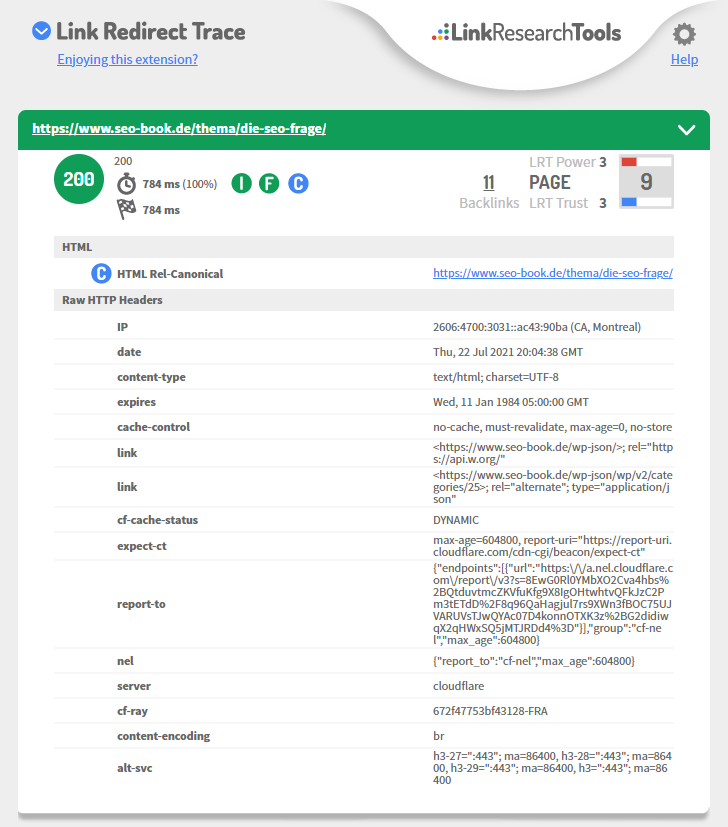
- Browser-Erweiterung: Mein Lieblings-Browser-Plugin ist Link Redirect Trace:
- Statuscode der Beispiel-URL ist „200“ -> Also alles „Ok“
- Robots Meta Tag ist nicht definiert oder steht auf „index“ -> erkennbar am grünen Icon mit dem weißen „I“
- Außerdem steht die Seite auf „follow“ -> erkennbar am grünen Icon mit dem weißen „F“
- Die Seite hat ein Canonical Tag (erkennbar am blauen Icon mit dem weißen „C“ sowie an der Zeile „HTML Rel-Canonical; das Canonical Tag verweist auf sich selbst; im HTTP Header ist kein Canonical gesetzt -> das Canonical ist selbstreferenzierend und steht der Indexierung nicht im Weg
-> Fazit: Die URL ist indexierbar!
- Crawler (am Beispiel Screaming Frog): Du kannst die URL auch mit dem Screaming Frog crawlen (z. B. im List-Modus einfach die URL crawlen, die du untersuchen möchtest) und den Indexierungsstatus prüfen. Dazu schaust du dir die Spalte „Indexability“ an. Dort muss „Indexable“ stehen, dann ist deine URL indexierbar. Steht dort „Non-Indexable“, erhältst du unter „Indexability Status“ noch Informationen, weshalb die URL nicht indexierbar ist.
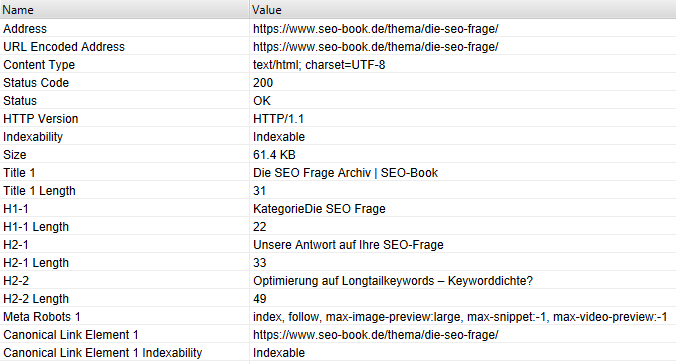
- Google Search Console: Außerdem kannst du die Indexierbarkeit einer URL auch über die Google Search Console prüfen.
- In der Google Search Console einloggen
- Entsprechende Property auswählen
- Im Menü „URL-Prüfung“ anklicken
- URL in das Eingabefeld kopieren und Eingabe bestätigen
- Du erhältst dann die Information, ob die URL indexierbar ist oder ob es Probleme gibt
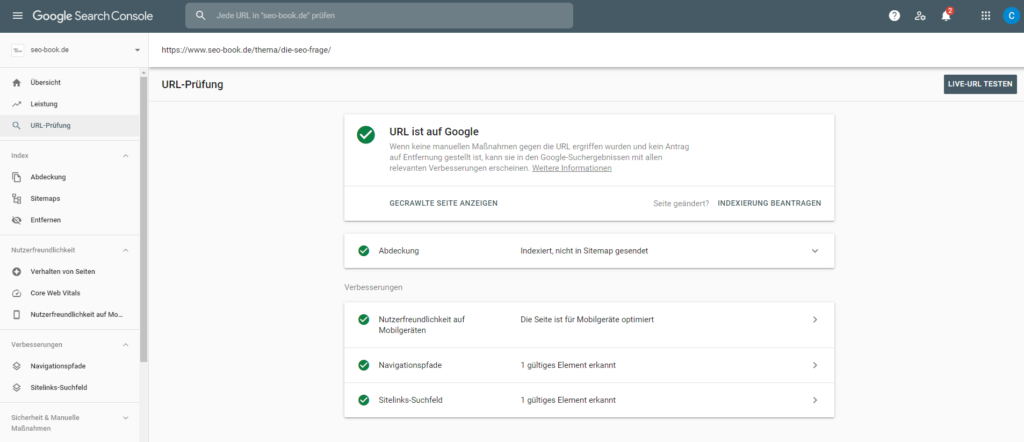
Wie kann ich den Indexierungsprozess beschleunigen?
Um den Indexierungsprozess zu beschleunigen gibt es verschiedene Möglichkeiten. Ich möchte dir hier die Wichtigsten vorstellen.
- Indexierung beantragen: Du kannst die URL über die Funktion „Indexierung beantragen“ unter „URL-Prüfung“ in der Google Search Console direkt anstoßen. Das ist im Grunde die sicherste Variante, da du hier direkt mit Google kommunizierst und die Indexierung direkt beantragst. In den allermeisten Fällen ist die URL dann bereits wenige Minuten später im Index (also mit einer site:-Abfrage) zu finden. Dieses Vorgehen eignet sich immer dann, wenn du neue Seiten erstellt oder Inhalte grundlegend überarbeitet hast und haben möchtest, dass Google diese neuen Infos möglichst sofort wahrnimmt und berücksichtigt.
- XML-Sitemap: Zusätzlich solltest du die gewünschte Seite/URL mittels XML-Sitemap an Google kommunizieren. Wie alle index-relevanten URLs sollte auch dein neu erstellter oder frisch überarbeiteter Inhalt automatisch in eine XML-Sitemap aufgenommen werden, die idealerweise in der Google Search Console eingereicht bzw. hinterlegt ist. Somit ist sichergestellt, dass der Googlebot die URL bei der nächsten Verarbeitung der XML-Sitemap findet und entsprechend indexiert.
- Interne Verlinkung: Last but not least solltest du die Inhalte auf deiner Seite prominent verlinken. Verlinke die Inhalte so häufig und prominent wie möglich, um die Chancen auf eine Indexierung deutlich zu erhöhen. Die besten Chancen auf eine Indexierung hast du beispielsweise dann, wenn du die neue Seite direkt von der Startseite und/oder aus dem Hauptmenü heraus anlinkst. Somit signalisierst du Google, dass die Seite dir wichtig ist und relevanten Inhalt für deine Besucher hat.


