
Jeder Webmaster kennt den HTTP Statuscode “404 Not found”. Denn der wird immer dann gesendet, wenn eine Seite oder Bild nicht (mehr) verfügbar ist – vorausgesetzt der Server ist richtig konfiguriert. Doch was hat es mit dem Statuscode auf sich? Wie sieht die perfekte 404-Fehlerseite aus und welche Varianten dieses Fehlercodes gibt es? All diese Fragen möchten wir hier klären.

Wann wird Statuscode 404 gesendet?
Statuscode 404 steht wie bereits erwähnt für “Not found” bzw. “Nicht gefunden”. Damit ist bereits geklärt, wann dieser Statuscode gesendet werden sollte, nämlich immer dann, wenn eine Ressource nicht mehr verfügbar ist. Das kann verschiedene Gründe haben.
Einige Beispiele:
So könnte beispielsweise ein Online Shop ein spezielles “Special” für einen besonderen Anlass, beispielsweise für das bevorstehende “Osterfest” gebastelt haben. Dieses Special ist dann natürlich nur bis Ostern relevant, nach den Osterfeiertagen interessiert es dann niemanden mehr. Clevere Inhouse SEOs lassen das Special natürlich so anlegen, dass die URL keine Jahreszahl enthält und auch ansonsten so gebaut ist, dass es im nächsten Jahr erneut verwendet werden kann. Es soll allerdings auch Redaktionen geben, die sich davon leider nicht abbringen lassen. Das sind dann auch die Kandidaten, bei denen das Special im Anschluss dann wieder aus dem Netz genommen wird. Die extra dafür angelegte URL www.domain.tld/ostern-2013.html liefert dann einen 404-Statuscode zurück.
Dass eine Ressource nicht mehr verfügbar ist, kann aber auch ganz andere Gründe haben. So könnten beispielsweise rechtliche Gründe dafür verantwortlich sein. Nehmen wir an, es wurde ein lizenzpflichtiges Bild eingebunden, für welches der Webmaster keine Lizenz erworben hat. Nachdem das Bild einige Tage auf der Website war, erhält der Webmaster eine Abmahnung und ist dazu verpflichtet das Bild vom Server zu löschen. Oft wird dann in der Hektik einfach nur das Bild gelöscht, die darauf verweisenden Links bzw. das für die Einbindung zuständige <img />-Tag wird jedoch vergessen. Auch in diesem Fall sendet der Server einen 404-Fehler.
Vermutlich am häufigsten kommt es jedoch durch technische Probleme zu 404-Fehlern. Beispielsweise durch eine Unachtsamkeit beim URL-Redesign oder andere technische Änderungen, die nicht gründlich genug getestet wurden. Ganze Relaunch-Projekte bzw. weitreichendere URL-Redesigns haben natürlich im Falle eines Fehlers die gravierendsten Auswirkungen, da hierdurch schnell einige tausend oder sogar zehntausende fehlerhafte URLs entstehen können.
Außerdem kann es zu weilen natürlich vorkommen, dass andere Websites fehlerhafte Links auf die eigene Website setzen.
Wie finde ich 404-Fehler auf meiner Website?
Google Webmaster Tools
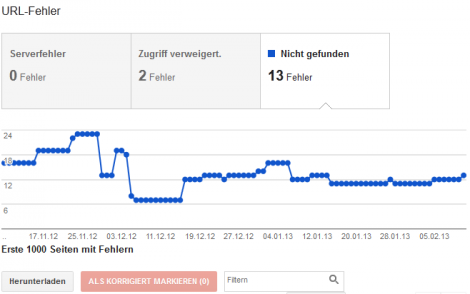
Der einfachste Weg 404-Fehler zu finden ist, zunächst einen Blick in die Google Webmaster Tools zu werfen. Dort listet Google unter “Status” -> “Crawling-Fehler” die verschiedenen Fehler auf. 404-Fehler sind dort gleich zweimal vertreten, einmal gekennzeichnet als “Nicht gefunden”, das sind die klassischen 404-Fehler und unter “Soft-404″, das sind streng genommen keine richtigen 404-Fehler. Aber dazu später. Diese Liste kann zur leichteren Verarbeitung auch heruntergeladen werden. Außerdem können die Fehler dort auch “als korrigiert” markiert werden, wenn sie gefixt wurden.
Crawler / Spider
Eine weitere Möglichkeit 404-Fehler aufzuspüren ist die Verwendung eines Crawlers bzw. Spiders. Wir empfehlen hierfür den Screaming Frog SEO Spider, Scrutiny oder den kostenlosen Xenu’s Link Sleuth aber auch das kostenlose SEO Toolkit von Microsoft liefert hervorragende Ergebnisse. Letzteres ist jedoch etwas komplexer bzw. umfangreicher.
Einmal heruntergeladen und installiert lässt man diese Tools die eigene Website crawlen und erhält anschließend unter anderem eine Liste aller gecrawlten URLs, die sich nach beliebigen Werten – z. B. nach HTTP Statuscode – sortieren lässt.
Das Searchmetrics Optimization Modul & der Sistrix Optimizer
Mittlerweile haben auch die Standard-SEO-Tools ein Optimization-Modul bzw. einen Optimizer. Sowohl bei Sistrix als auch bei Searchmetrics hat der User die Möglichkeit ein eigenes Projekt anzulegen, dazu wird die Domain der Website eingetragen, ggfs. noch ein Name für das Projekt vergeben und eine Liste mit Keywords hinterlegt. Auf die Keywords möchten wir an dieser Stelle nicht eingehen, uns interessieren die Onpage-Optimierungsvorschläge bzw. in vorliegenden Fall eigentlich nur die 404-Fehler.
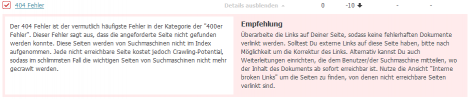
Beide Tools listen also die vom Crawler entdeckten Seiten auf, die Statuscode 404 senden. Searchmetrics gibt außerdem gleich noch eine Empfehlung, was mit diesen Fehlern passieren sollte.
Onpage.org & strucr.com
Wer sich die Allround-SEO-Tools nicht leisten kann oder möchte, aber trotzdem mehr Komfort bzw. eine übersichtlichere Darstellung als in den Crawlern bevorzugt, dem stehen mit onpage.org (inzwischen ryte.com) und strucr.com (inzwischen Audisto.com) zwei hervorragende webbassierte Tools zur Verfügung. Das Besondere an den beiden Tools: sie befassen sich ausschließlich mit dem Onpage-Potential der Seite und liefern jede Menge Daten.
Link Research Tools
Ein weiteres ausgezeichnetes Tool zum Aufspüren toter Links ist das Modul “Link Juice Recovery Tool” aus den Link Research Tools. Auch damit lassen sich hervorragend Seiten finden, die wertvolle Backlinks erhalten haben, allerdings mittlerweile Statuscode 404 senden. Also hier geht es nicht um die intern verlinkten Fehlerseiten sondern die von extern.
Wie sollten 404-Fehler behandelt werden?
Zunächst sollte der Server so konfiguriert werden, dass er weiß, wie er mit Ressourcen umzugehen hat, die nicht bzw. nicht mehr existieren. Wenn das nicht automatisch eingestellt ist, erreichen wir das durch folgende Zeile in der .htaccess-Datei:
ErrorDocument 404 /404.php
Damit sagen wir dem Server, dass er Anfragen, die er nicht beantworten kann an das Dokument 404.php deligieren soll (es kann natürlich auch ein anderes Dokument angegeben werden). Im Script kann dann genau definiert werden, wie mit der nicht gefundenen Ressource umgegangen werden soll. Generell kann hier zwischen zwei Möglichkeiten unterschieden werden: Den Request auswerten und via 301-Redirect an eine ähnliche Ressource weiterleiten oder aber Status-Code “404 Not found” senden und eine entsprechende Fehlermeldung anzeigen.
Hinweis: Wichtig ist beim Eintrag in der .htaccess-Datei übrigens, dass alles vor dem ersten Slash weggelassen wird. Wird dies nicht berücksichtigt und das Dokument wie folgt angegeben:
ErrorDocument 404 https://www.domain.tld/404.php
so findet zunächst ein Redirect (je nach Serverkonfiguration ein 302 oder eben ein 301) statt. Das Resultat davon sind sogenannte Soft-404-Fehler.
Was sind Soft-404-Fehler?
Um einen Soft-404-Fehler handelt es sich dann, wenn eine Seite aufgerufen werden soll, die nicht vorhanden ist und die zwar nach einer Fehlerseite aussieht, also beispielsweise für 404-Seiten typischen Content enthält, aber einen “falschen” Statuscode sendet. Der richtige Statuscode für eine Fehlerseite ist logischerweise “404 Not Found”.
Zur Verdeutlichung ein kleines Beispiel. Es wird eine Seite aufgerufen, die nicht existiert und folgenden Text enthält:
404 Not Found
Die angeforderte URL konnte nicht gefunden werden.
Wird für diese Ressource jedoch Statuscode “200 OK” oder “302 Found” zurückgeliefert, so spricht Google von einem Soft-404-Fehler, meint: es steht zwar 404-Fehler drauf, es ist jedoch kein 404-Fehler drin. Google bringt hier auch einen Vergleich mit einer Giraffe, die ein Namensschild mit “Hund” um den Hals trägt.
Nur weil “Hund” drauf steht, ist noch lange keine Hund drin. Nur weil eine Seite einen 404-Fehler anzeigt, heißt das also nicht, dass sie einen 404-Fehler zurückgibt.
Wichtig ist also, dass ein 404-Dokument auch den korrekten Statuscode, nämlich “404 Not Found” bzw. “410 Gone” zurückliefert.

Google weißt übrigens auch darauf hin, dass es problematisch sein kann, wenn anstelle von Statuscode 404 eine Weiterleitung auf eine andere Seite, beispielsweise die Startseite vorgenommen wird. Dies könnte von Google als Soft-404-Fehler gewertet werden und die “Crawling-Abdeckung der Website beeinträchtigen”. Nicht mehr vorhandene Inhalte sollten also lt. Google nicht weitergeleitet werden, sondern Statuscode 404 senden, da der Benutzer eine bestimmte Erwartungshaltung an die Seite hat und diese nicht erfüllt wird, wenn er sich auf einmal auf der Startseite der entsprechenden Seite befindet. Das klingt nicht nur logisch, sondern macht auch Sinn.
Mehr Informationen zum Thema Soft-404 findet ihr direkt bei Google.
Übrigens: In der Tat berichten einige Kollegen davon, dass die früher so beliebte Strategie, eine expired Domain kaufen und die nicht mehr vorhandenen Unterseiten einfach alle auf die Startseite umleiten um deren Linkjuice an die Startseite weiterzuleiten, mittlerweile nicht mehr funktionieren soll. Da fehlt uns allerdings die Erfahrung, da wir nicht mit expired Domains und anderen Tricks arbeiten. Deshalb die Frage an euch: Funktioniert das heutzutage noch?
Doch zurück zur Frage, wie man 404-Fehler behandelt: Ihr wisst nun, wie man den Server konfiguriert, damit er überhaupt ein entsprechendes Error Document verwendet und den korrekten Statuscode zurückliefert. Doch was mache ich nun mit den 404-Fehlern? Wie so oft lautet die Antwort: kommt darauf an! 😉
Zunächst muss zwischen internen und externen 404-Fehlern unterschieden werden.
Externe 404-Fehler
Externe 404-Fehler können sehr wertvoll sein, nämlich genau dann, wenn starke Seiten auf Inhalte unserer Website verlinken, die nicht mehr existieren. Das kann eine Unterseite, ein PDF oder auch ein Bild sein. In diesem Fall schlägt die Linkkraft auf unserer 404-Fehlerseite auf, was natürlich suboptimal ist, da wir mit dieser Seite ja nicht ranken möchten. In diesem Fall sollte ein möglichst gutes internes Linkziel gesucht und eine 301-Weiterleitung darauf eingerichtet werden. Wichtig ist jedoch, dass der User dort den Inhalt findet, den er glaubte zu finden, nachdem er auf der externen Seite auf den Link klickte. Existiert keine Unterseite mit entsprechend passendem Content, so sollte laut Google also weiterhin ein 404 gesendet werden. Früher hätte man an dieser Stelle eine 301-Weiterleitung auf die Startseite eingerichtet. Dies ist aufgrund der unter “Soft-404-Fehler” beschriebenen Problematik jedoch nur noch eingeschränkt zu empfehlen.
Hinweis: Sauberer als solche falsch gesetzten Links auf passende Ziele umzuleiten ist es natürlich, den jeweiligen Webmaster anzuschreiben und zu bitten, den Link zu korrigieren. Das sollte selbstverständlich oberste Priorität haben. Nur wenn dieser nicht reagiert oder sich weigert den Link zu ändern, sollte entsprechend umgeleitet werden.
Externe 404-Fehler von Spam-Seiten, wie beispielsweise webstatsdomain[dot]com, die in letzter Zeit leider gehäuft in den Google Webmaster Tools vorzufinden sind, sind in der Regel von so geringer Qualität, dass es sich nicht lohnt, sie weiterzuleiten. Da es sich hierbei häufig um gar keine richtigen Links handelt und vermutlich alle Seiten mit diesen Links zu kämpfen haben, kann davon ausgegangen werden, dass Google diesen Spam erkennt und entsprechend behandelt. Eine besondere Behandlung ist aus unserer Sicht nicht notwendig.
Interne 404-Fehler
Im Gegensatz zu externen 404-Fehlern sind Interne 404-Fehler immer von Bedeutung. Der simple Grund: sie können in der Regel gefixt werden. Und das sollten sie auch. Denn eine Seite mit vielen 404-Fehlern macht nicht nur einen ungepflegten Eindruck, sondern kann auch Probleme beim Crawling bekommen. Denn der Crawler kommt in der Regel immer nur mit begrenzten Kapazitäten. Werden diese jedoch immer wieder für fehlerhafte Seiten verschwendet, so könnte dazu führen, dass die Seite immer unattraktiver für den Crawler wird und dieser immer weniger Seiten crawlt. Davon abgesehen hält es ihn davon ab, die relevanten Seiten zu crawlen. Je größer eine Website, desto mehr 404-Fehler weisen die Google Webmaster Tools in der Regel auf. Das muss nicht immer schlimm sein, aus eben beschriebenen Gründen – und auch der User wegen – sollte jedoch darauf geachtet werden, dass die Zahl der Crawling-Fehler möglichst gering gehalten wird.
Tipp: Wer so viele 404-Fehler auf seiner Seite hat, dass er gar nicht weiß, wo er anfangen soll, dem sei dazu geraten zunächst die Fehler zu fixen, die intern und/oder extern die meisten eingehenden Links haben.
Was gehört zu einer guten 404-Seite?
Eine gute 404-Seite sollte demnach folgende Kriterien erfüllen:
- Korrekter Statuscode: Wie bereits mehrfach angesprochen, sollte eine 404-Seite auf jeden Fall den richtigen Statuscode, also “404 Not Found” oder aber “410 Gone” zurückliefern.
- Aussagekräftige Fehlermeldung: Während für Suchmaschinen in erster Linie der Statuscode eine wichtige Rolle spielt, so kann der User damit in der Regel nichts anfangen, da er diese Information nicht sieht. Deshalb ist es wichtig, dass für den User eine aussagekräftige Fehlermeldung bereit gehalten wird. Diese sollte kurz und prägnant gehalten sein und den User darüber informieren, dass die angeforderte Ressource leider nicht mehr zur Verfügung steht.
- Navigationsmöglichkeit: Wenn die Inhalte schon nicht mehr verfügbar sind, sollte dem User zumindest die Möglichkeit geboten werden, die gewohnte Navigation der Website zu nutzen, um beispielsweise Kontakt zum Seitenbetreiber aufzunehmen oder nach ähnlichen Themen zu suchen.
- Seiten mit ähnlichem Content: Wer die Möglichkeit hat, den Request auszuwerten und entsprechend zu verarbeiten, der sollte dem User neben einer Fehlermeldung und der üblichen Navigation auch gleich passende Ziele mit ähnlichem Content vorschlagen. Das erhöht die Wahrscheinlichkeit, dass der User auf der Seite gehalten werden kann und nicht bounct enorm.
- Suchfunktion: Zusätzlich zu den gewohnten Navigationsmöglichkeiten, kann auch eine Suchfunktion auf der Fehlerseite integriert werden. Der User hat dann die Möglichkeit direkt nach einer Alternative zu suchen und bleibt auf der Seite.
Das war – hoffentlich wirklich – alles zum Thema 404-Fehlerseite. Fällt euch noch etwas ein? Haben wir etwas nicht gut genug erklärt? Würdet ihr etwas grundlegend anders machen? Wir freuen uns auf eure Kommentare!





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}